About topic
Know About topic
Page Replacement Algorithms
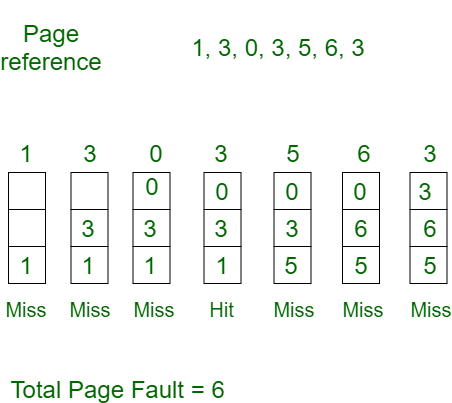
First In First Out
First In First Out
Advantages
1).It is simple and easy to understand and implement.
2).It is efficiently used for small systems.
3).It does not cause more overheads.
Disadvantages
1).The process effectiveness is low.
2).When we increase the number of frames while using FIFO, we are giving more memory to
processes. So, page fault should decrease, but here the page faults are increasing. This
problem is called as Belady's Anomaly.
3).Every frame needs to be taken account off.
4).It uses an additional data structure.

Optimal
Optimal
Advantages
1).Complexity is less and easy to implement.
2).Assistance needed is low i.e Data Structure used are easy and light.
Disadvantages
1).Not possible in practice as the operating system cannot know future requests.
2).Error handling is tough.
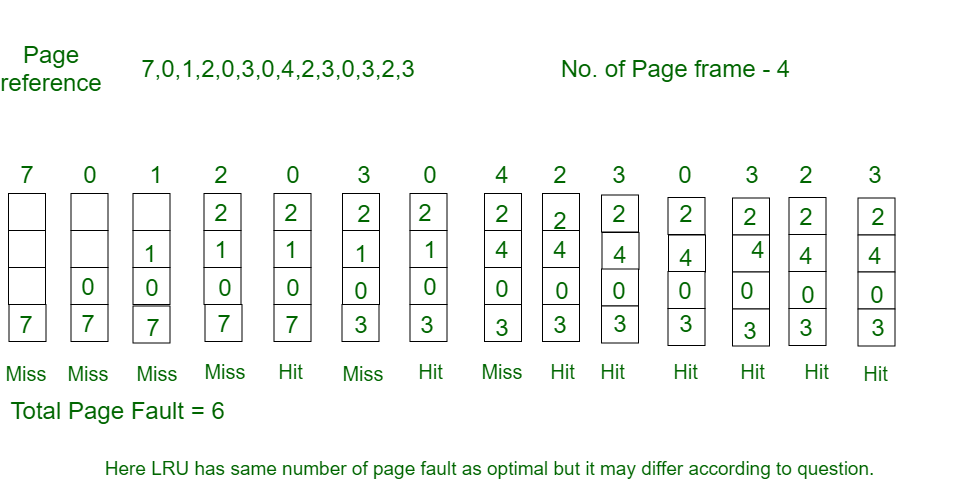
Least Recently Used
Least Recently Used
Advantages
1).It is open for full analysis.
2).In this, we replace the page which is least recently used, thus free from Belady's
Anomaly.
3).Easy to choose page which has faulted and hasn't been used for a long time.
Disadvantages
1).It requires additional Data Structure to be implemented.
2).Hardware assistance is high.
3).In LRU error detection is difficult as compared to other algorithms.
4).It has limited acceptability.
5).LRU are very costly to operate.
F.A.Q
Frequently Asked Questions
We will be updating the rest of the questions soon
-
What are Memory fit Algorithms ?
Memory fit algorithms are algorithms that are used to allocate contiguos memory to processes when there are certain gaps in the memory and some memory is unoccupied by processes and forms holes.
-
Why do we need memory fit algorithms ?
We need these algorithms to efficiently allocate contiguos memry to processes and try to avoid fragmentation to some extent.
-
What is the advantage of next fit over first fit ?
Next fit tries to address this problem by starting the search for the free portion of parts not from the start of the memory, but from where it ends last time. Next fit is a very fast searching algorithm and is also comparatively faster than First Fit and Best Fit Memory Management Algorithms.